Weakly Supervised Segmentation of Hyper-Reflective Foci with Compact Convolutional Transformers and SAM2
Jan 10, 2025
Exploring Drusen Type and Appearance using Interpretable GANs
Sep 19, 2024
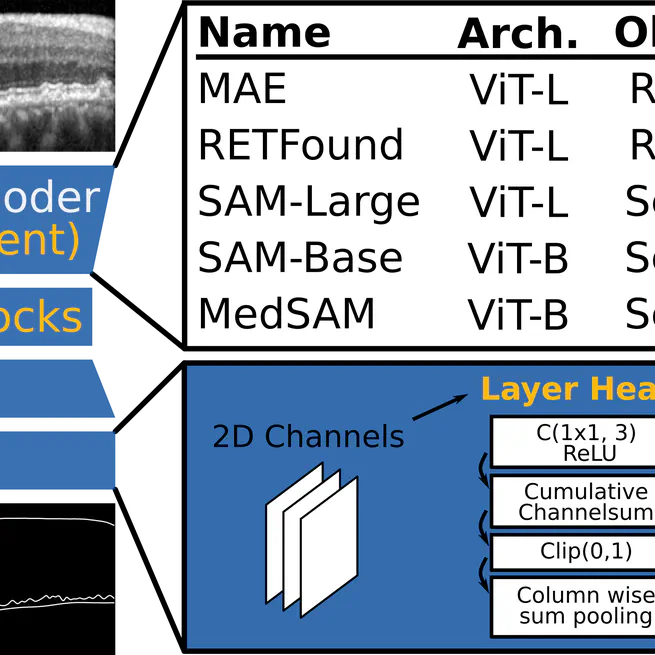
Foundation Models Permit Retinal Layer Segmentation Across OCT Devices
Segmenting retinal layers in OCT images is crucial for ophthalmological diagnosis, but current CNN models struggle with images from different devices. We introduce the first OCT layer segmentation method using Vision Transformer (ViT) foundation models, which significantly improve generalization to unseen devices and demonstrate that generic foundation models outperform equally large OCT-specific models in robustness.
Sep 10, 2024